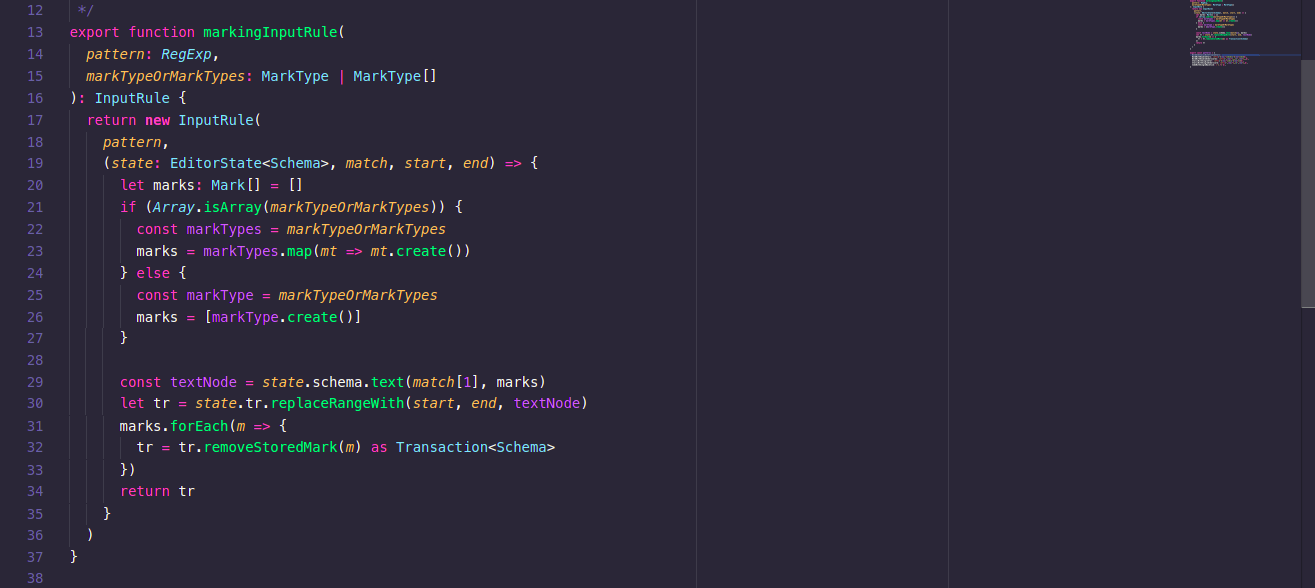

In ProseMirror, you can write InputRules, which trigger certain actions when a given pattern of text is typed in the editor and matched by a RegExp.
There are already many examples of InputRules in prosemirror-example-setup that help you create different types of block nodes. So, in this article, we talk about writing ones for creating inline styles like **bold** and *italic*.
Explanation
Naive
To match **bold**, you write:
/**(.+)**$/But this does not work if you also need to match *italic*, let’s say, with:
/*(.+)*$/Why? Because when you type **bold*, it triggers the match of /*(.+)*$/, so the text becomes *bold, and you have no chance of typing the final *.
However, if there’re no overlapping cases, like `code`, this naive version works fine.
Robust
To match **bold**, you write:
/(?<=[^*\n]|^)\*\*([^*\n]+)\*\*$/The first part (?<=[^*\n]|^) uses a Positive Lookbehind operator (?<=...) to tell the regex engine to match something, but not to add it to the match (so when you want to match x**abc**, you don't get the "x" in the result). [^*\n] says to match a character that is not * or \n. |^ says to also match the beginning of a line.
The second part is trivial. \*\* matches two *s, to find the first two characters of **bold**. \ escapes * to treat it as a character.
We can now go back to the first part. The reason of the first part is to ensure that there’re no *s before ** that we want to match, so we can match exactly two *s. If there’re three, we don’t match, so other rules that match three works.
The third part ([^*\n]+) is to capture the text between the pair of **. + says that it’ll match one or more characters. [^*\n] excludes *, since * would suggest the end of the pair, and \n, since we’re matching inline styles, so no newline!
The final part \*\*$ ensures the end of the pair.
In conclusion, there’re four parts in this regex structure — Guard + Match the Start + Wrapping Text + Ensure the End. Now we can write more regexes based on this structure.
Examples & Test Cases
- Remember to turn on
/gm(global, multiline) for your regex engine.
Bold and Italic with Triple Stars
Regex:
/(?<=[^*\n]|^)\*\*\*([^*\n]+)\*\*\*$/Match:
***123***
5***123***
***1***No match:
****123***
***123**
**123***
***123Bold with Double Stars
Regex:
/(?<=[^*\n]|^)\*\*([^*\n]+)\*\*$/Match:
**123**
5**123**
**1**No match:
***123**
**123*
*123**
**123Bold with Double Underscores
Regex:
/(?<=[^_\n]|^)__([^_\n]+)__$/Match:
__123__
5__123__
__1__No match:
____
__123_
_123_
__123Italic with Single Star
Regex:
/(?<=[^*\n]|^)\*([^*\n]+)\*$/Match:
*123*
5*123*
*1*No Match:
**123**
**123*
*123**
*123Italic with Single Underscore
Regex:
/(?<=[^_\n]|^)_([^_\n]+)_$/Match:
_123_
5_123_
_1_No match:
__
__123_
__123__
_123